
本章前面部分探讨过给现有比特币所有者配置新的另类币的两种方法:或者要求用户把比特币销毁从而得到另类币,或者简单地把另类币发给现有比特币所有者,这些所有者必须拥有还没有用掉的比特币。正如我们看到的,任何一种方式都不需要另类币的价格盯住比特币。没有这种汇率锁定机制,在发展初期,另类币的价格会变化很大。侧链(sidechains)的目的就是避免另类币价格变化太大,因为价格的波动太大会导致很多问题,也会使另类币分心乏术,无法真正专注于技术上的竞争。
下面介绍使另类币的价格以固定汇率的形式盯住比特币的相关技术。首先,所有者必须把所拥有的一定数量的比特币放入托管账户,这样才能创造出一个单位的另类币(或者固定单位的另类币),这样所有者才可以在另类币区块链上正常使用另类币。最后,所有者必须能够销毁自己拥有的另类币,从而取回之前存在托管账户上的比特币。这种构建像零币,通过托管基础币而创造零币。区别在于,需要在两个不同的区块链里进行上述操作。
遗憾的是,据我们了解,由于比特币的交易无法被其他区块链的事件所影响,目前还未找到可以不改动比特币而达到这种效果的方法。截至目前,比特币的脚本还没有强大到可以确认整个单独的区块链。好消息是,我们可以通过相对实用一点的软分叉来修改比特币,这也是侧链的原理。侧链的愿景是,将比特币作为储备货币,打造多种蓬勃发展、快速创新和实验的另类币。截至2015年,侧链还只是一个提案。但是比特币社区正在积极参与这个提案,目前已取得一些实质性的进展。侧链的提案还处于变化之中,所以为了便于学习和理解,我们适当简化了一些细节。
扩展比特币的功能,使之能够使侧链兑换成比特币,最显而易见但不太实用的办法是:把所有侧链的规则,包括验证所有侧链的交易和检查侧链的工作量证明,都包含在比特币体系里。这个方法不实用是因为这样会使比特币扩展出来的程序过于复杂,验证比特币的节点会非常困难。而且,链接上的侧链越多,复杂度和困难度就越大。
SPV技巧
可以使用SPV证明技巧来避免这种复杂局面。在第3章中,我们曾提到简单付款验证(Simple Payment Verification,简称SPV)。SPV可用于小的客户端,比如手机上的比特币应用程序(APP)。SPV节点不需要对其不感兴趣的交易做验证,它们只校验区块的标题。SPV客户只看他们感兴趣的交易,并确信是在最长的区块链内,并不担心该链是否是最长的有效链。因为他们假定矿工在创建该区块链并花精力去挖矿之前,已经验证过里面的交易了。
也许,可以扩展比特币的脚本让它能验证侧链里某些特殊的交易(比如销毁一个侧链币的交易)。在比特币里使用这种延展命令的节点,仍然会全面验证比特币的区块链,但是在侧链里,可能只会验证相对轻量级的SPV。
对一个交易提出异议
这种方法要好一些,但仍不完美。即使做最简化的验证,比特币的节点仍然要链接到侧链的点对点网络(每个链接上比特币的侧链都需要如此),并且追踪所有侧链区块的标题用于决定侧链最长的分支。最终我们想要的是:当一个交易要把侧链的货币转化成为比特币时,它本身就包含比特币节点需要的用于验证其合法性的所有信息,也就是说,验证特定的侧链是真实发生的。这就是SPV证明的定义。
这里介绍一种可行的办法,唯一的缺憾是这个侧链的组成部分还在进一步研究中。为了在比特币里可以对照到侧链,用户必须证明:(1)侧链区块里包含侧链交易;(2)侧链的标题表明这个区块已经接受过一定次数的认证,这意味着一定数目的工作量证明。比特币会验证这些证明,但是不会去验证这个区块头部展示的链是最长的。相反,比特币会等一定的时间,比如1~2天,让其他用户去找证据证明,第二步所指向的区块标题并不在最长分支上。一旦在特定时间范围内出现这样的证据,比特币体系中,接受该侧链交易的区块将会被认定为无效。
隐含的逻辑是:如果一个SPV证明已经可以确定,该交易不在最长分支上致使其不应该被认可,那么应该有一些侧链的用户会因认可这个交易而遭受损失。这些可能遭受损失的用户,有动力去辩驳SPV证明。如果没有用户遭受损失(也许是有一个分支,或者重组侧链,而且该交易也恰好在别的分支上),那接受这个证明也无妨。
一般来说,系统这样设计,对侧链问题并非毫无漏洞,系统也不会阻止你自己搬石头砸自己的脚。如果你把比特币转成有加密隐患的侧链,其他人也许能偷走你的侧链币然后再转成比特币。或者,在侧链的挖矿,也许会因为侧链漏洞而全部崩溃,导致对应的比特币也被偷。但是可以肯定的是,侧链的问题不会毁掉比特币;具体地说,不管侧链有多少漏洞,所有者都无法在侧链上兑现两次同一货币,也就是说侧链不允许比特币挖矿。
通过权益证明精简SPV证明的案例
还有一个障碍需要跨越。有些侧链生成区块的速度很快,也许每几秒钟就能产生一个区块。这种情况下,对比特币节点来说,单单验证SPV证明就已经负担很重了。这时,可以用一个比较聪明的统计学方法,大幅减少对N个区块的验证,也就是大幅减少O(N)的认证次数。
原理如下:当验证深藏在区块链中的一个区块,其实是在验证每个建立在这个区块上的所有的区块都符合目标困难度(target difficulty), 即满足哈希值<目标值。这些区块的哈希值均匀地分布在(0,目标值)的区域,从统计学角度看,这意味着大约25%的区块可以满足哈希值<目标值/4. 事实上,寻找N/4个区块满足哈希值<目标值/4的工作量和计算N个区块满足哈希值<目标值的工作量一样。这个数字4并无特别,我们可以用任何数代替。
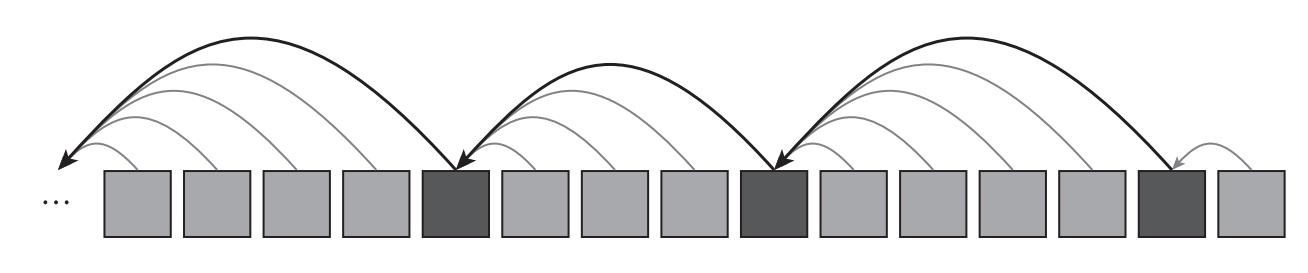
图10.7 工作证明跳表(proof-of-work skip list)[1]
注:区块包含指向前面一个区块的指针和指向最近的满足哈希值<目标/4的指针。这个原理可以重复运用,比如一个第三层级的指针指向满足哈希值<目标值/16[2]
这就意味着如果找到某种方法可以知道哪些区块满足哈希值<目标值/4,仅验证这些区块(或者区块的头部)就可以使用1/4的工作量完成全部任务。如何找到哪些区块满足哈希值<目标值/4呢?其实答案在区块本身。图10.7显示,每个区块包含指向前面一个区块的指针,以及指向最近的满足哈希值<目标/4的指针。
可以压低目标值到多小?是否可以选择很大的数,让目标值变得非常小?答案是否定的。这种方式的原理就像矿池,却是反方向的操作。在矿池里,矿池管理员验证大家的份额,也就是验证这些难度系数低(比较高的目标值)的区块。矿工找到比区块更多的份额,所以矿池管理员必须多做一道验证程序的工作。这样做的好处就是,能够比较精准地估计矿工的哈希算力——估计值的方差较小。
我们来看相反的交易。随着估算建造整个区块链的工作的减少,估算值就有很大的方差。例如,假设N=4,在没有使用跳表的方案下,会检测到有4个区块满足哈希值<目标值。如果一个恶意的竞争对手要欺骗我们,他需要花4倍于我们找到一个区块的平均工作量才能办到。
假设这个竞争对手只做了一半的工作。可以算出,竞争对手有14%的机会能找到4个区块满足哈希值<目标值。相反,在跳表方案下用4作为倍数,竞争对手的任务变成需要找到一个区块,满足哈希值<目标值/4。在这种情况下,懒惰的只做了一半工作的竞争对手,却有40%的机会骗过我们,而不仅仅是14%。
[1] 跳表是一种随机化的数据结构,目前开源软件Redis和LevelDB都有用到它。——译者注
[2] 16是2的1+3次方。——译者注,以此类推。